![]()
![]() 生成模型的偏好对齐,可能正在进入一个新的阶段。
生成模型的偏好对齐,可能正在进入一个新的阶段。
过去几年,大模型 post-training 最主流的方法是让模型从"成对偏好"中学习。但无论是 RLHF 还是 DPO,都存在同一个问题:反馈必须成对出现。
但在真实场景中,反馈大多都是单个样本的标量分数。

为此,新加坡国立大学团队提出了一个更为直接的解法:Threshold-Guided Optimization ( TGO ) ,一种不依赖成对偏好数据、直接利用独立样本标量评分进行对齐的新范式。
简单来说,就是从分数分布中估计一个阈值,高于阈值的样本被看作 pseudo-positive,低于阈值的样本被看作 pseudo-negative;训练时,模型提高前者相对 reference model 的概率,降低后者的概率。
同时,样本分数离阈值越远,说明监督越确定,训练权重也越大。
目前该研究已被ICML 2026接收,它让生成模型对齐不再只依赖"哪个更好",而是开始直接利用"这个有多好"。

DPO 的优雅,来自 pairwise data
DPO之所以能成为偏好优化里的代表方法,一个关键原因是它把原本复杂的 KL-regularized RL objective,改写成了一个可以直接训练的分类目标。
在这个目标里,模型不需要显式训练 reward model,也不需要像 PPO 那样做在线 rollout,只要有离线的偏好对,就能完成 policy fitting。
它背后的数学结构也很清楚:
在 KL 正则化的对齐目标下,最优策略可以写成一个 closed-form solution。但这个解里有一个 partition function,也就是归一化项,需要对所有可能输出求和,通常不可计算。
DPO 能绕开这个问题,是因为在同一个 prompt 下比较 preferred output 和 rejected output 时,这个 partition function 会在 reward difference 里自然抵消。
也就是说,DPO 的简洁,很大程度上来自成对偏好数据本身。两个输出一比较,难算的项就消失了,问题也就变成了一个相对概率的分类问题。
但这个优势也反过来限制了它的适用范围。
一旦监督信号不再是 pair,而是单个样本的 scalar score,原来靠"两两相减"抵消 partition function 的办法就不再直接成立。
于是实践中常见的做法,是把标量分数转成偏好对。例如在一个 batch 内排序,把高分样本当作 winner,低分样本当作 loser;或者对同一 prompt 下多个候选结果两两比较,再构造 chosen/rejected pair。
这种做法当然可以用,但它也会带来信息损失。
一个 9.5 分样本和一个 7.5 分样本,在 pairwise 训练里可能都只是 winner;一个 4.9 分样本和一个 4.8 分样本,也可能被硬拆成一组 winner 和 loser。
当前后两个样本差距很小、评分噪声又比较大时,这种人为构造出来的偏好对未必可靠,甚至可能放大错误监督。
对于视觉生成来说,这个问题更突出。
图像和视频的质量很少是简单的二元判断。图像可能审美不错但文本对齐一般,也可能构图准确但风格不够好;视频还要考虑运动是否自然、主体是否稳定、时间是否连贯。
很多时候,一个连续分数比一个 winner/loser 标签更接近真实反馈。
三条路线,都在放松 pairwise 约束
至于研究团队新提出的 TGO,也并非孤立出现。最近领域内好几篇工作其实都在回应同一个问题:偏好优化能不能不再强依赖成对偏好?
PMPO
首先是 Google DeepMind 最近发布的《Preference Optimization as Probabilistic Inference》一文。
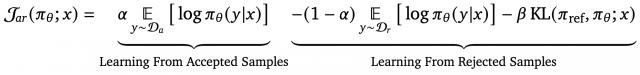
它的出发点是,模型并不一定需要看到严格配对的 preferred/dis-preferred samples,才能学习偏好。
只要有 preferred examples 或 dis-preferred examples,甚至只有其中一种反馈,也可以进行优化。

方法上,它基于 EM-style policy improvement,把目标写成三个部分:提高 preferred samples 的 likelihood,降低 dis-preferred samples 的 likelihood,同时让新策略保持接近 reference policy。
这条路线的重点,是反馈结构更灵活。传统 DPO 需要一个 prompt 下的 chosen 和 rejected 配成一对,而PMPO允许正负样本不成对出现,也允许数据分布不平衡。
这对很多现实任务是有意义的,因为真实数据里经常只有"这个结果不错"或者"这个结果不行",而不是完整的两两比较。
QRPO
论文《Quantile Reward Policy Optimization: Alignment with Pointwise Regression and Exact Partition Functions》则解决的是另一个方向的问题:
如果我们手里有的不是正负标签,而是 pointwise absolute reward,能不能直接做 policy fitting?
这背后仍然绕不开partition function。

QRPO的做法是把原始 reward 转成 quantile reward。这样,在 reference policy 下,quantile reward 的分布会变成 uniform distribution,partition function 也就有了解析形式。
元股证券:ygzq.hk
于是模型可以用一个简单的 pointwise regression objective,直接拟合 KL-regularized objective 的最优策略,而不需要依赖成对比较来抵消归一化项。
TGO
而本文《Threshold-Guided Optimization for Visual Generative Models》回答的亦是同一个问题,只不过和 PMPO、QRPO 处理的是相同问题的不同切面。

PMPO 关心 unpaired positive/negative feedback,QRPO 关心 pointwise absolute reward 的可解析 policy fitting,而 TGO 则面向视觉生成模型,选择了一个更轻量的 threshold 方案。
三者的共同点,是都在把偏好优化从"必须有 pair "这个前提里松开。
TGO 的核心:用阈值近似 baseline
具体来说,TGO 的方法看似简单,但并非单纯拍一个阈值出来做二分类。它背后的推导来自KL-regularized alignment objective。
这就引出一个问题:对于一个给定样本,最优策略到底应该提高它的概率,还是降低它的概率?
在理论上,这取决于它的 reward 是否超过某个 instance-specific oracle baseline。如果 reward 高于这个 baseline,那么模型应该提高该样本相对 reference model 的概率;如果 reward 低于 baseline,就应该降低它的概率。
但这个 oracle baseline 和 partition function 有关,通常不可计算。
DPO 的做法是用成对比较让它抵消掉;QRPO 的做法是通过 quantile transformation 让 partition function 变得可解析;TGO 则选择用一个driven global threshold来近似它。
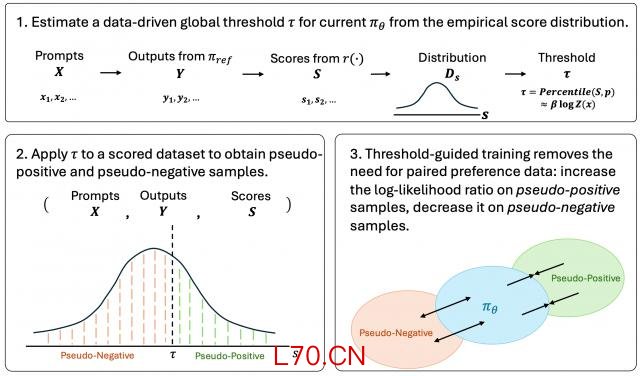
TGO 先从 scored dataset 的分数分布中估计一个阈值。
最常见的选择是 percentile threshold,比如中位数。之后,所有分数高于阈值的样本被视为 pseudo-positive,低于阈值的样本被视为 pseudo-negative。
训练时,模型学习调整自己相对于 reference model 的 log-likelihood ratio:对 pseudo-positive 样本提高,对 pseudo-negative 样本降低。
更进一步,TGO 还引入了confidence weighting。分数离阈值越远,说明这个样本被判为正例或负例的置信度越高,它对训练的贡献也应该越大。分数接近阈值的样本则更模糊,训练时权重更低。
这样一来,TGO 并没有完全丢掉标量分数的幅度信息,而是把分数大小转化成了监督强度。
所以,TGO 的规则可以概括为两层:阈值决定更新方向,距离决定更新力度。
这也是它和普通二值化的区别。普通二值化只保留正负标签,而 TGO 的 confidence weighting 继续利用了分数离阈值的程度。
对于视觉生成这种评分噪声较大、质量分布连续的任务,这一点很重要。
需要注意的是,TGO 并不消除对反馈质量的依赖。标量分数仍然需要与目标偏好足够相关;如果打分器有偏或噪声较大,阈值产生的 pseudo-label 也会继承这些偏差。
持牌可查配资平台因此,TGO 解决的是如何更直接地利用 scalar feedback,而不是替代反馈建模本身。
为什么视觉生成尤其适合 scalar feedback
语言模型里,成对偏好很自然。人类比较两个回答哪个更好,很多时候确实比直接打分更稳定。但在视觉生成里,情况并不完全一样。
一张图好不好,往往不是一个简单的"胜过另一张图"就能说明。它可能在审美上很好,但 prompt alignment 稍弱;也可能语义准确,但构图普通;还有一些偏好更主观,比如风格、色调、人物姿态、背景复杂度。
这些因素叠在一起,更适合被表达成一个连续分数,或者多个维度的评分。
视频生成更是如此。视频不仅要看单帧质量,还要看运动合理性、时间一致性、主体稳定性、镜头变化以及文本对齐。
把这些信号强行压成一个 pairwise preference,往往会损失很多细节。
真实产品里的反馈也更接近 scalar 或 implicit feedback。用户可能点赞、收藏、点击、停留、打分,或者对生成结果做二次编辑。
这些信号并不天然成对,却是模型改进非常重要的数据来源。如果对齐方法只能处理 winner/loser,就很难充分利用这类反馈。
TGO 针对的正是这个缺口。它不要求每个 prompt 下都有多个候选结果,也不要求人为构造偏好对。只要每个样本有一个分数,就可以进入训练。
这让视觉生成模型的对齐,更接近真实反馈的收集方式。
从图像到视频:TGO 在多种视觉生成范式上验证
论文的实验覆盖了两类视觉生成范式:一类是diffusion-based models,另一类是masked generative models。
前者包括 Stable Diffusion v1.5、FLUX、Wan 1.3B 等常见模型,后者则包括 Meissonic 这样的 masked generative transformer。
这说明TGO 并不是只适配某一种模型结构。对于 diffusion model,它可以结合 MSE-style objective;对于 MaskGIT 风格的离散生成模型,它也可以基于 token likelihood 做训练。
换句话说,TGO 更像是一种通用的 scalar-feedback alignment framework,而不是某个特定架构上的技巧。
在图像生成实验中,TGO 在 Pick-a-Pic、PartiPrompts 和 HPSv2 等测试集上进行评估,并使用 HPSv2.1、PickScore、ImageReward、CLIPScore、LAION Aesthetic Score 等多个 reward model 作为评价指标。
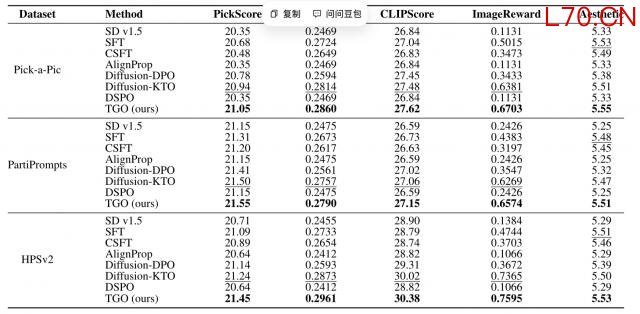
结果显示,相比 SFT、CSFT、AlignProp、Diffusion-DPO、Diffusion-KTO、DSPO 等方法,TGO 在多个设置下都能取得更高的 reward-model scores。
视觉生成对齐里,一个常见担忧是 reward hacking:模型可能只是把某一个 reward model 刷高了,但生成质量并没有真正改善。
TGO 在多个 reward model 上都有提升,说明它并不是单纯拟合某个打分器,而是在更广泛的视觉偏好维度上带来了改进。
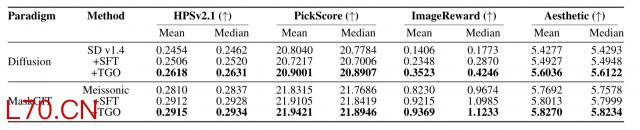
在视频生成上,TGO-LoRA 也被用于 Wan 1.3B+VideoReward 的实验设置。结果显示,它不仅提升了整体 VideoReward score,也改善了多个组件指标。
这说明 threshold-guided scalar feedback 不只是图像生成里的一个局部方法,也有潜力扩展到视频生成。
不是替代 DPO,而是补上另一种反馈接口
但TGO 并不是要否定 DPO。
成对偏好仍然很重要,在很多任务里也仍然是最稳定、最直观的反馈形式。尤其是当人类很难给出绝对分数,但能比较两个结果好坏时,pairwise preference 仍然有很强的实用价值。
但问题在于,pairwise preference 不应该是唯一接口。
生成模型正在进入更多真实应用场景,而真实场景里的反馈并不会总是以 chosen/rejected pair 的形式出现。
语言模型会有 reward model score、verifiable reward、数学验证结果、代码通过率;图像模型会有审美分数、图文对齐分数、人类评分;视频模型会有运动质量、时间一致性和视频文本对齐;多模态系统还会有点击、收藏、停留、编辑等用户行为信号。
这些反馈大多是 pointwise 的。它们不告诉模型"这个比另一个更好",而是告诉模型"这个结果本身有多好"。如果对齐方法只能处理比较数据,就会错过大量自然存在的监督信号。
PMPO、QRPO 和 TGO 的共同意义,正在于把偏好优化从 pairwise supervision 扩展到更一般的 feedback optimization。
PMPO 说明,未配对的正负反馈可以被纳入概率推断式的 policy improvement;QRPO 说明,绝对奖励也可以通过 quantile reward 进入可解析的 policy fitting;TGO 则说明,在视觉生成里,一个经验阈值加置信度权重,就足以把 scalar score 转成有效的对齐信号。
那么为什么这件事如今值得被认真对待呢?
因为生成模型越往产品里走,反馈形态就越复杂。
早期的对齐研究可以假设有干净的偏好对,但真实用户不会总是配合系统做 A/B comparison。

更多时候,系统拿到的是一个分数、一次点击、一次收藏、一次停留,或者一次修改。这些信号看起来零散,却可能构成下一阶段 post-training 的主要数据来源。
对于视觉生成尤其如此。图像和视频的质量,本来就不是非黑即白的判断,而是审美、语义、结构、运动、风格和个体偏好的综合结果。直接从 scalar feedback 中学习,可能比先构造成对偏好更自然,也更容易扩展。
TGO 的价值就在这里。它没有把问题复杂化,而是用一个很克制的方式,把标量反馈接进了 KL-regularized alignment objective。
理论上,它用经验阈值近似不可计算的 oracle baseline;工程上,它只需要 scored samples 就能训练;实践上,它能同时覆盖 diffusion 和 masked generative paradigms,并在图像和视频任务上带来稳定提升。
这可能是生成模型对齐接下来很重要的一步:模型不能只会从"谁赢了"中学习,也要能从"这个结果有多好"中学习。

总的来说,过去,偏好优化的主流接口是 pairwise comparison。这个接口足够清晰,也催生了 DPO/GRPO 这样简单有效的方法。
但随着生成模型进入更复杂的应用场景,反馈本身正在变得更加多样。评分、通过率、奖励模型输出、用户行为日志、编辑操作,这些 pointwise signals 会越来越常见。
TGO 给出的答案很直接:不一定要把它们都折叠成 winner 和 loser。对于视觉生成模型,只要找到一个合理的阈值,就可以把标量分数转成更新方向;再用分数离阈值的距离,衡量这个监督信号有多可信。
这并不是一个复杂的系统,也不是一个重型 RL pipeline。它更像是把真实反馈里本来就存在的信息,以更直接的方式交给模型。
如果说 DPO 让偏好优化摆脱了复杂 RL,那么 TGO、QRPO 和 PMPO 这一类工作,正在让偏好优化进一步摆脱对成对比较的强依赖。
生成模型对齐的下一步,可能不只是继续问"哪个更好"。而是要让模型真正学会理解:这个结果到底有多好。
参考文献:
[ 1 ] Preference Optimization as Probabilistic Inference, https://arxiv.org/abs/2410.04166
[ 2 ] Quantile Reward Policy Optimization: Alignment with Pointwise Regression and Exact Partition Functions, https://arxiv.org/abs/2507.08068
[ 3 ] Threshold-Guided Optimization for Visual Generative Models, https://arxiv.org/abs/2605.04653
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注 AI 的学术编辑实习生 � �
感兴趣的小伙伴欢迎关注 � � 了解详情

� � 点亮星标 � �
科技前沿进展每日见配资公司费用对比
24 小时杠杆配资开户提示:本文来自互联网,不代表本网站观点。


